笔记来源—
卡尔曼滤波算法原理及代码实现!![]() https://www.bilibili.com/video/BV1WZ4y1F7VN/?spm_id_from=333.337.search-card.all.click&vd_source=8d55784dc9c7530bc9e3fa220380be56
https://www.bilibili.com/video/BV1WZ4y1F7VN/?spm_id_from=333.337.search-card.all.click&vd_source=8d55784dc9c7530bc9e3fa220380be56
简单介绍一下
现在我们就是不知道是距离多少,就需要用到这个卡尔曼滤波器。

这里的预测方程就是我们的状态方程
这里的一般就是单位矩阵 ,或者是单位矩阵的一部分
这里的一般就是状态变量的个数,
就是你选择的观测值
具体是什么形状要根据选择的状态变量
以及要观测的目标值的
的形状
所以上面我们举的小车的例子的观测值就只有一个,那就是他的距离,所以就是1*1的矩阵,
就是1,如果我们还想知道车速,那么
就是2.
就是2*1的矩阵
举个例子

状态变量的个数等于状态方程的个数乘以他的阶数,这里他只有一个方程
首先要看他是一个几自由度的模型,这个RLC模型他是一个1自由度的系统,所以他只涉及一个方程,因为他只有一个回路,一个方程就可以把这个系统表示了。本质上他是一个单自由度系统。一个单自由度系统就写一个方程,这个方程他又是一个二阶的方程,所以选两个状态变量。
这里我们的求导是为了些状态方程。
这里的是系统矩阵,
是控制矩阵
代表的就是在k-1时候的状态,
就是我们的控制量,一般我们在基尔霍夫数据中里面一般是认为没有控制量,所以这一项基本上为0,再加上我们的噪声
就得到了预测方程
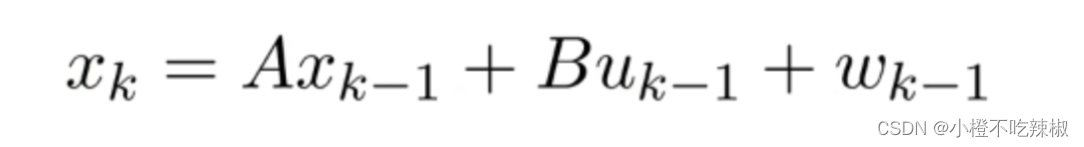
问题来了,那么我们的观测方程又是什么?
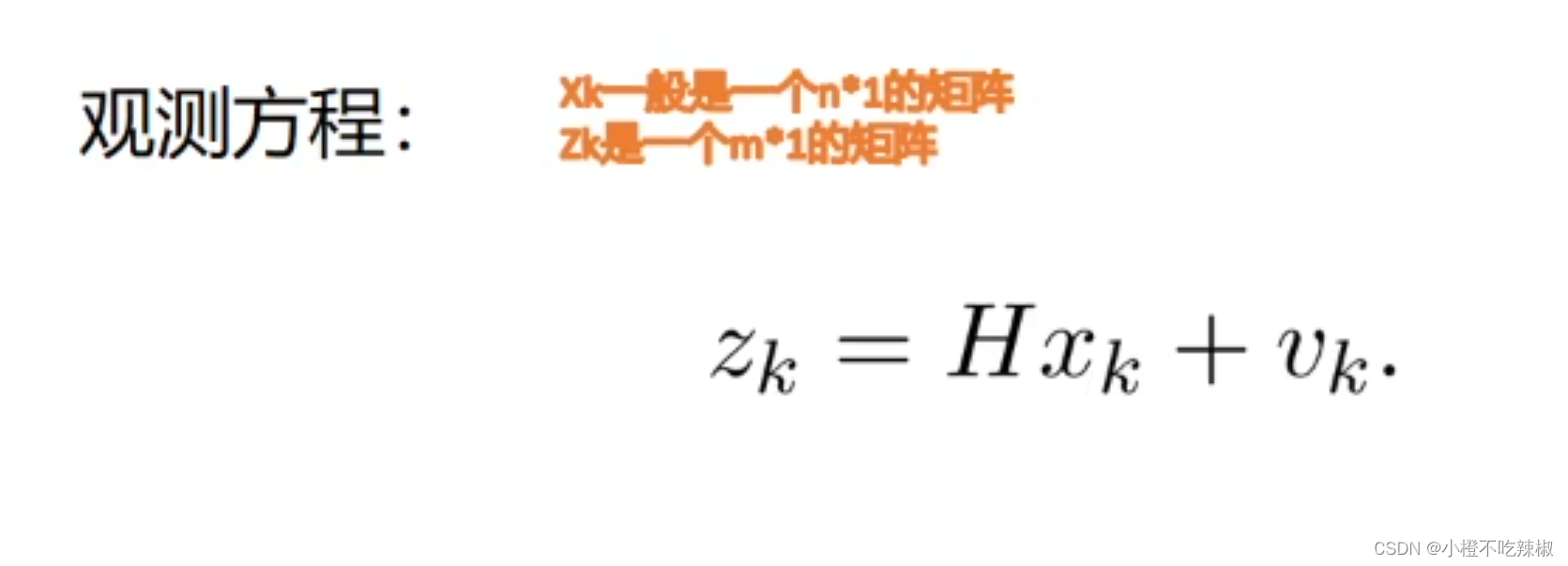
H到底是什么?
H其实就是一个单位阵,继续用那个例子
我们的
是由我们自己决定的,也就是说你做卡尔曼滤波就是你决定的,①比如是电流
的话我们的
=
.②比如还想要
,那么
。
在第一种情况下我们的
也就是说,我们只要知道
跟
就可以知道我们的
如果我们选第二种,那么我们的,但是他应该是
,因为什么呢,因为
无法观测到,写了1就说明观测的到,但是我们观测不到所以这里是0.

我们的目标就是找到最优的估计值,先验就是我们要通过我们的预测方程来达到一个预测估计值
就是说我们已经测量
了,也就是说已经拿到预测值
还有测量值
了,我们对他进行矫正,矫正得到了一个最优的估计值,然后就会得到我们的先验估计误差和后验估计误差
下面就是我们的预测方程,上面讲过

然后我们找到了先验估计误差跟后验估计误差,就有了先验估计误差的协方差还有后验估计误差的协方差
优化思路
卡尔曼滤波详细解释

我们对一个硬币进行测量三次,那我们怎么去估计这个值呢,一般我们的第一思路就是求平均值
经过转换我们可以看到这个等式
随着k的增加我们可以知道,这个趋近于0

这个也很好理解,就是说当我们有了大量的数据,我们对估计的结果就很有信心了
数据比较少的时候,作用就大了

让我们换种表达方式

可以 看到我们的新一次的估计值与上一次的估计值有关,上一次的就跟上上一次的有关,这就是卡尔曼滤波的递归思想。

这个时候我们引入估计误差跟测量误差的概念,我们可以知道当估计误差远大于测量误差的时候,我们的卡尔曼增益是趋近于1的,这个时候我们就带入原来的公式,可以看到我们的估计值是等于测量值的,也就是说我们更加相信这个测量值。
当估计误差远小于测量误差的时候,我们的卡尔曼增益系数就接近于0,我们的估计值就相信上一次的估计值
举个例子
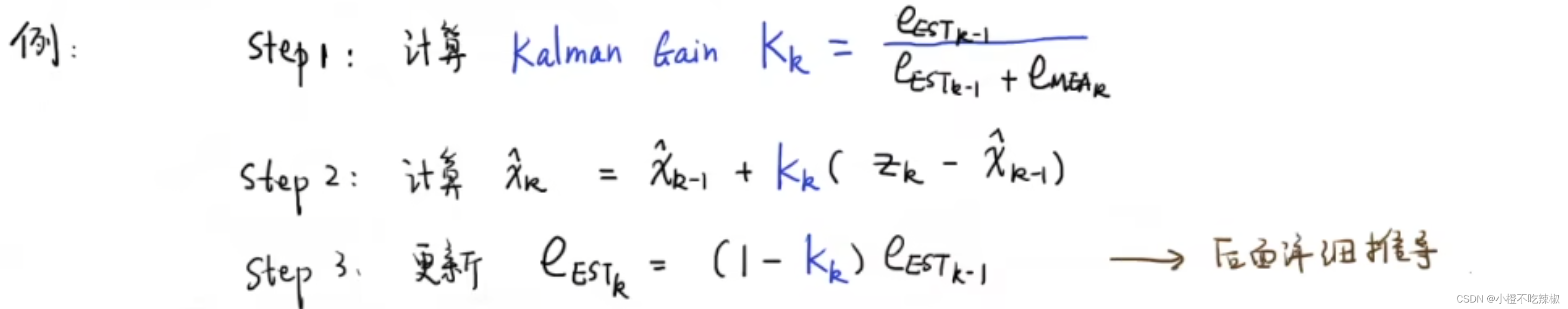
我们先引入三个公式,前面两个就是我们上面推出来的公式,第三个是我们的更新估计误差的公式

再引入我们的数据,还是测长度。
我们的实际长度是50mm,估计长度是40mm,估计误差在5mm,我们第一次的测量值为51mm,测量误差是3mm,也就是说我们测量的值在48-54mm之间,使用的是同一个测量工具,所以它第几次的测量误差都是3mm

然后我们就可以进行计算

然后我们继续进行第二次的计算
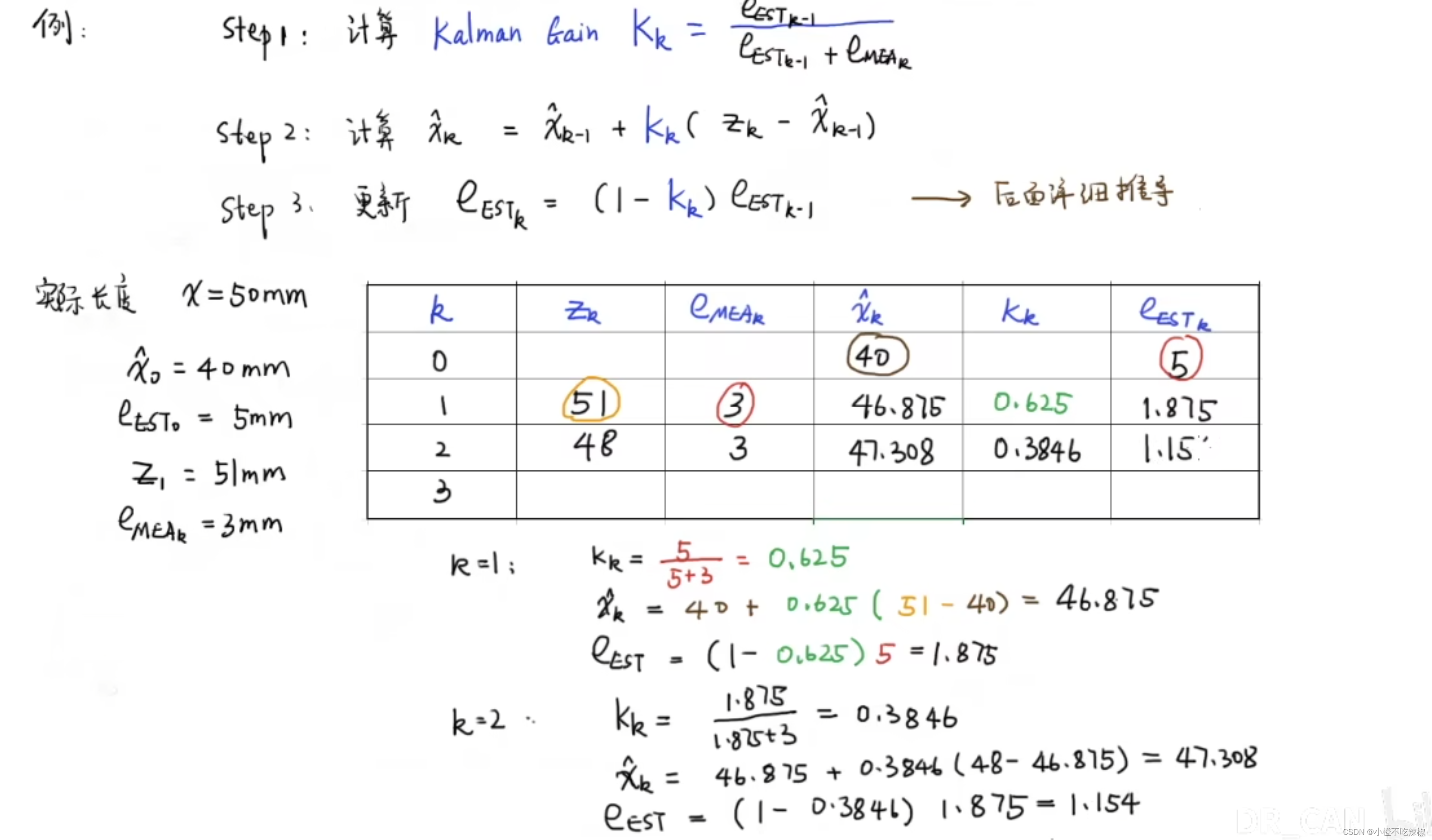
我们第二次测量的值为48,测量误差还是3mm
我们继续进行计算,可以看到我们的卡尔曼增益根据上一次的估计误差进行了更新
我们的估计值也由于卡尔曼的增益和上一次的估计值进行了更新
我们的估计误差根据我们的卡尔曼增益跟上一次的估计误差进行了更新
然后剩下的我们使用excel进行计算

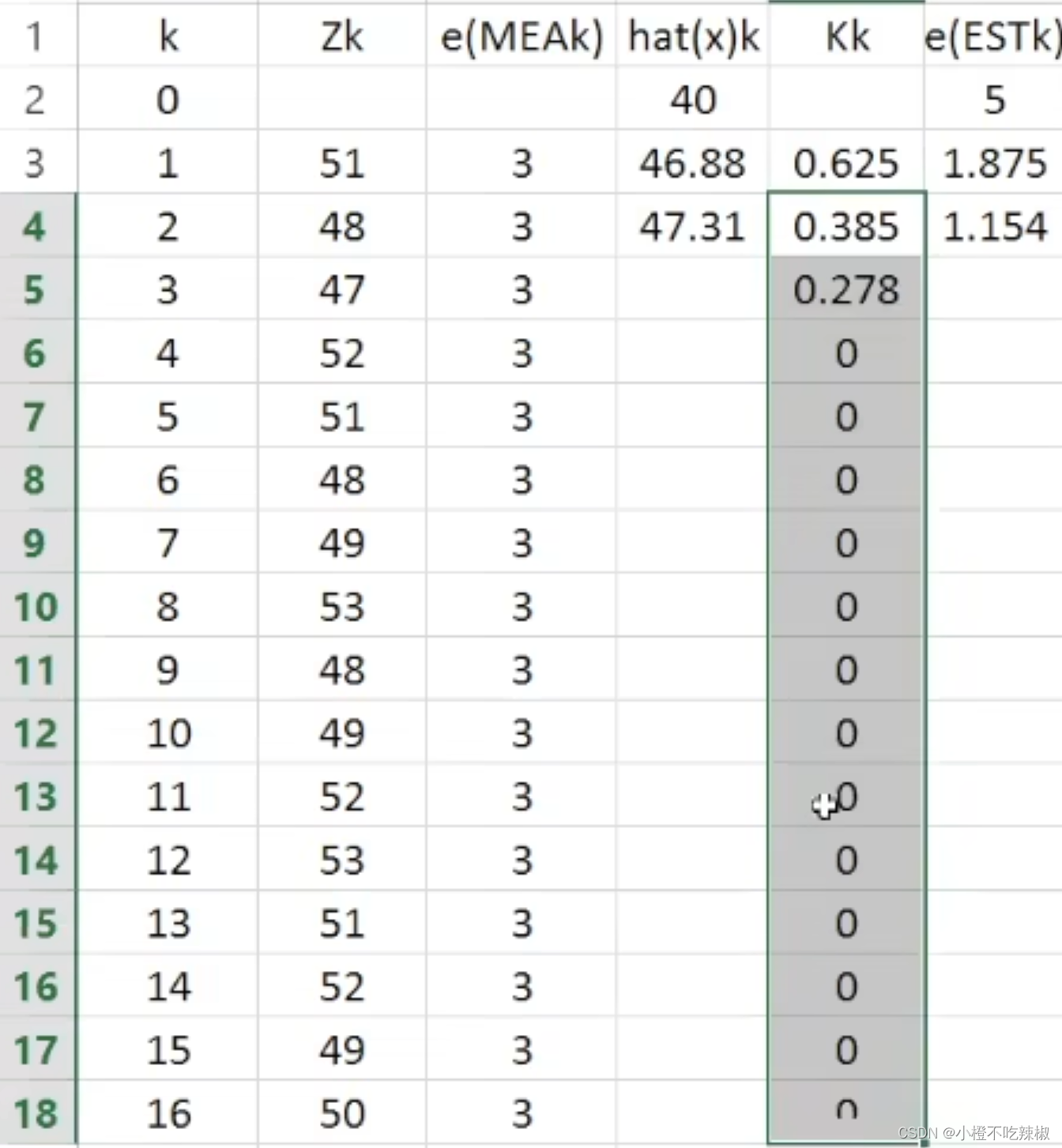
我们的测量误差就是3,只要保证在50上下范围3左右浮动就可以了
然后先计算我们的

再计算我们的估计值

再计算我们的估计误差
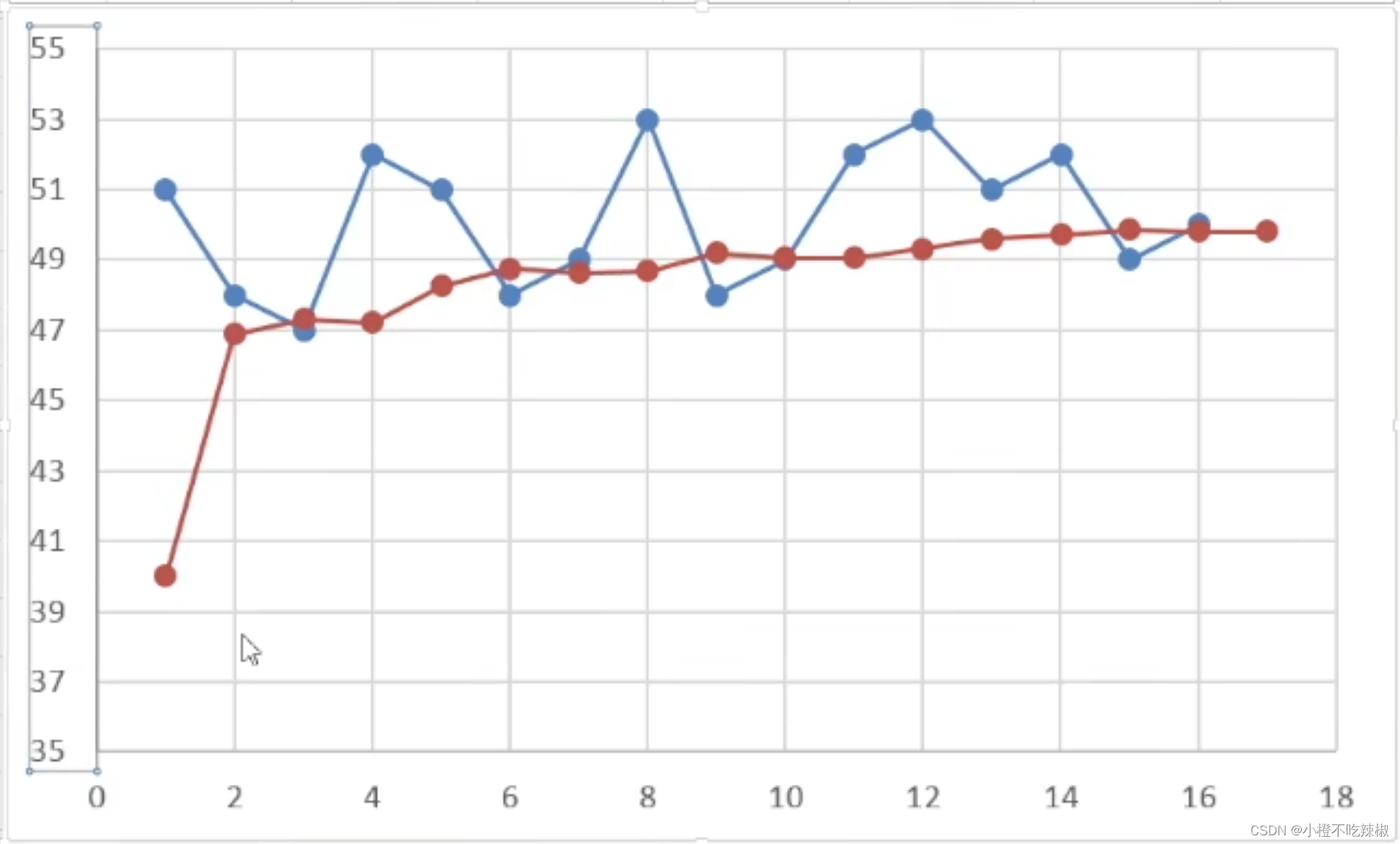
这里可以看到这里的蓝色是我们的测量结果,红色是我们估计的结果,我们的估计值从一开始的40开始上升,慢慢逐渐到我们的49附近,再慢慢靠近我们的实际值,我们知道这个50是我们的实际尺寸
数学基础——数据融合,协方差矩阵,状态空间方程,观测器
方差


这两个是一样的
数据融合——Data Fusion
假设我们现在有两个称,去称一个东西,得到两个结果,而且我们知道这两个称都不准,得到两个结果一个是,另一个是

我们可以知道他的正态分布和概率(积分可以算)
机器视觉中应用正态分布
正态分布概率计算
不知道正态分布的的可以看一下上面这两个链接
这时候我们知道了这两个结果,这个时候我们要去估算这两个真实值,是多少呢?
凭感觉来讲,应该是在这两个分布的中间,而且第一个的误差小,因为他的标准差小

所以真实值更靠近第一个称称出来的结果,大概在绿线的位置
如果要从数学上找到一个最优的估计值应该怎么做?
这个时候就要用到我们之前所说的Kalman Gain的思想了

下面我们就是要去求解K了,就是使得我们的估计值的标准差最小,也就是方差最小
为什么?
因为方差越小越接近真实值

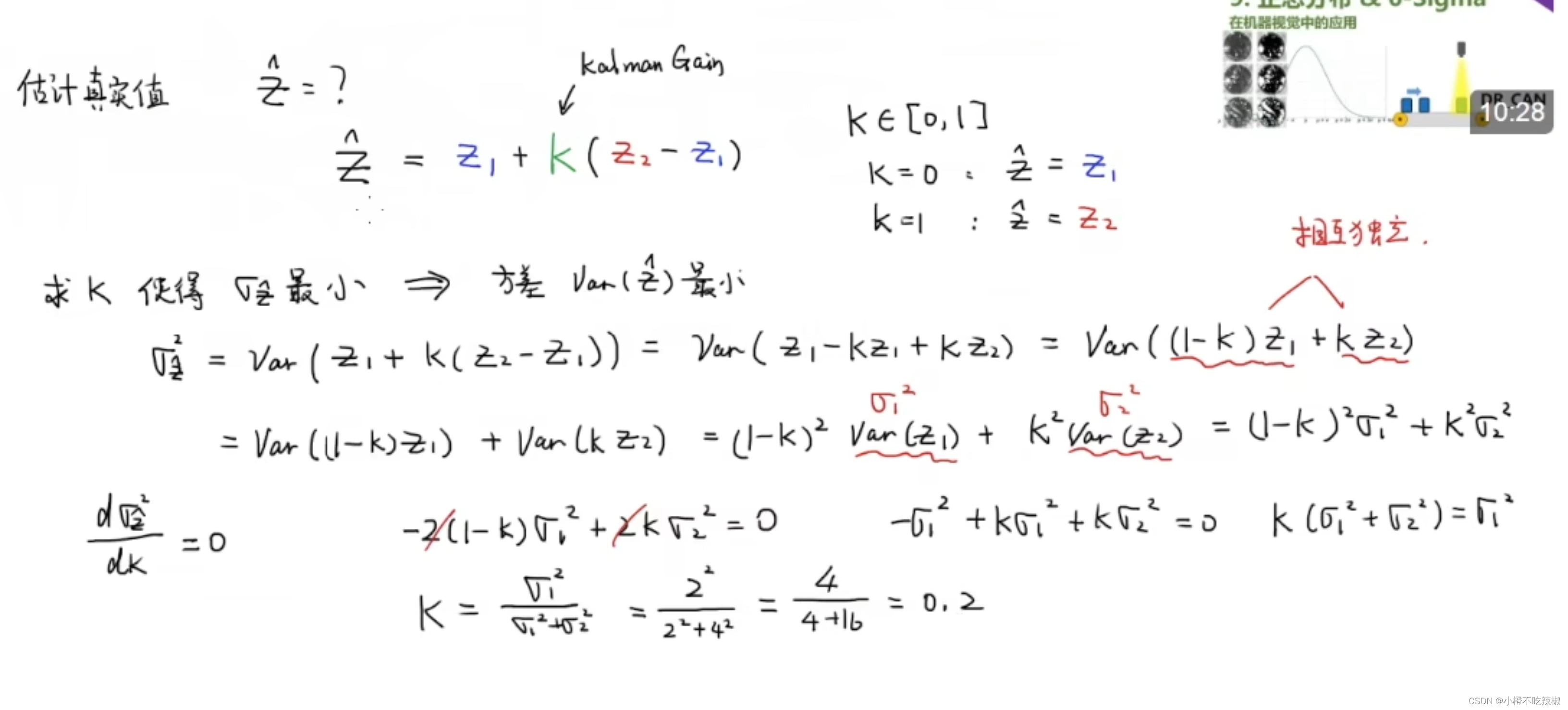
对其求导(令他为0),可以得到我们的极值,然后再带入我们的方差值,就可以知道我们的k了
有了k以后我们再把k带入上面的式子

可以得到

也就是说,根据这两个称的特性测量出来的结果我们做出了预测,这个预测就是30.4g,并且通过数学证明了他就是最优解
回到我们之前的这一步,我们,这时候我们就可以去更新我们的估计误差
这个时候去计算他的方差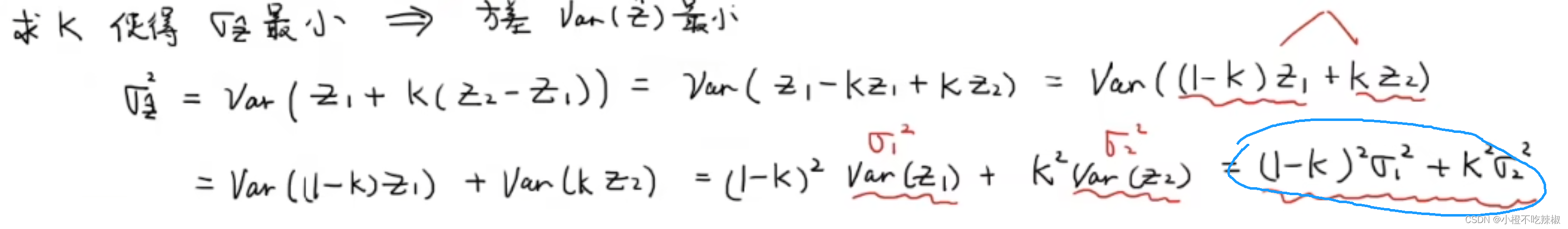
带入到蓝色的地方

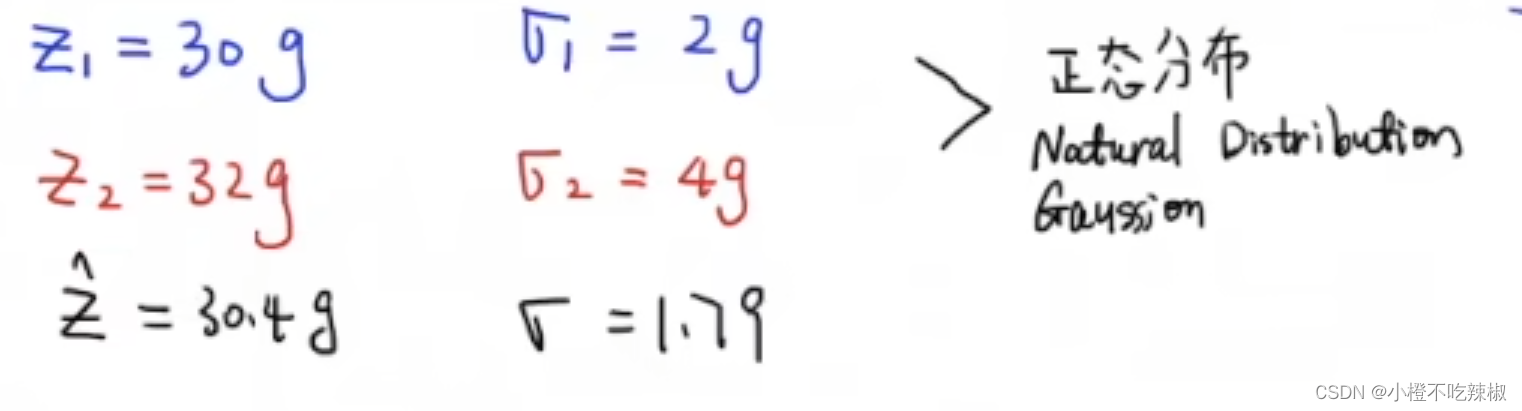
就得到了我们估计值跟估计误差(方差)

这就是他的图,这个过程就叫做数据融合
协方差矩阵
举个例子

这里我们取三个人最基本的数据,身高,体重,年龄。并求平均值,方差,协方差
从这里的协方差可以反应出如果这里两个相乘项都小于平均值,那么两个数相乘都是正的,如果都大于平均值,两个数相乘也是正的。如果一个大一个小,那么两个值相乘就是负的了。
结果:1、如果求出来的协方差两个值都是正的话,那就说明这两个变量方向就是一样的(正相关)
2、如果是负的话,那就说明这两个变量变化方向是相反的

同样我们可以求出来另外两个的协方差
然后我们的协方差矩阵就是这种形式,带入数据,我们就可以分析各个数据之间的关系了

然后我们再可以扩展一下,在扩展之前,我们分析一下
如何通过矩阵的运算来计算协方差
首先我们去求一个过渡矩阵

我们可以知道a矩阵的后面两个矩阵相乘再乘三分之一就是一个求平均值
计算一下,其实就是对应的,通过这样的方法我们就能算出来协方差矩阵了
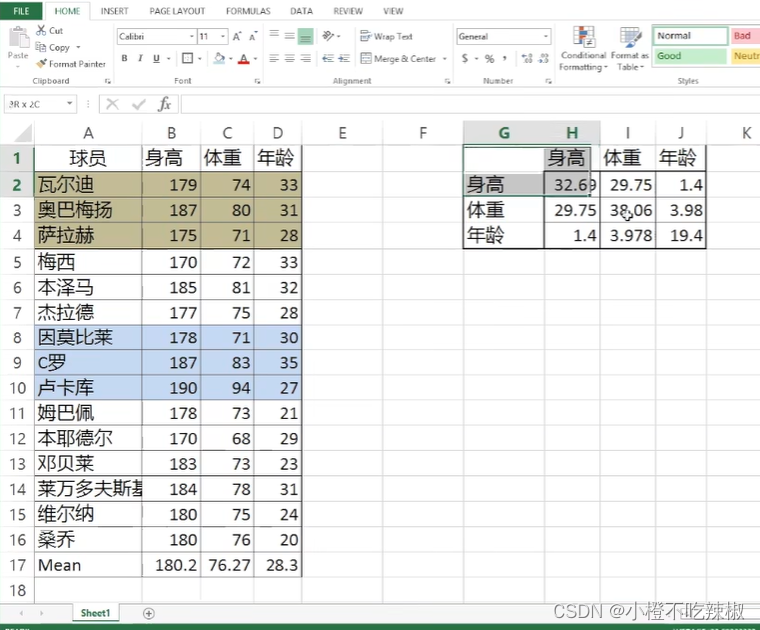
这里我们给出了15个队员,然后右边的就是他们的协方差矩阵,我们先看对角线的数据
可以看到他们之间的方差变化是蛮大的

也就是说如果想成为射手的话,并不局限于身高和体重,年龄的跨度也是比较大的,19.4的方差相当于有四岁多的标准差,±4岁也就是8岁,跨度也是不少的,所以说一个射手的年龄关系不是特别大。
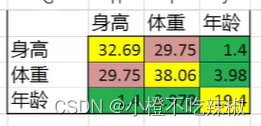
首先我们看体重跟身高,首先就是29.75,说明体重跟身高是非常正相关的,随着身高增加体重也增加,然后我们看年龄跟体重,年龄跟身高,他们之间的相关性非常小。说明对于这些运动员来说
他们的身高体重年龄就没有太多的关系。
状态空间表达
现代控制理论就是以状态空间为基础的,有兴趣可以看这个up主的视频
【Advanced控制理论】1_介绍_哔哩哔哩_bilibili
这里我们给出最基础的概念
例子
一个弹簧阻尼系统,质量为m,向右施加的力为F,向右的方向是x,弹簧的胡克系数是k,B是他的阻尼系数。他的动态方程如下图所示
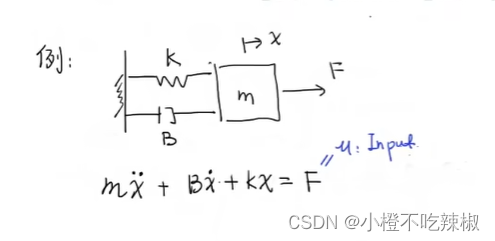
然后我们可以把F定义为u,也就是系统的输入。
首先我们把他化成状态空间的表达式就是首先要确定两个状态变量。

然后做一个等量代换,就用两个一阶微分方程把这个形式表达出来了。
如果我们这里还有测量量,我们可以把它定义为Z1,测的是他的位置,Z2测的就是它的速度

然后我们把上面的4个式子用矩阵的方式紧凑的表达出来
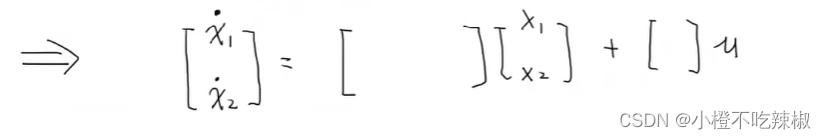
我们就去填一个数

根据上面的式子可以得到
而测量的方程就可以这样表达

完整的表达

这就是状态空间的表达形式
我们可以归纳一下(蓝字)

这就是一种连续的表达形式
我们可以看到状态变量的方程哪里有对Xt的导数,体现了随时间的变化
如果我们将其写成离散的形式,每相隔一个时刻来看一下这个变化的话,就可以写成这样的形式

这里的下标k,k-1,k+1每一个单位1都代表了一个时间单位,叫做sample time(采样时间)也代表了一种变化趋势
从离散型到连续型并不是照抄上面的矩阵结果,需要根据采样时间来进行计算(不是这次重点讨论的结果,只需要记得基本的概念),体现的是一种变化,从上一步到这一步的变化。
然后我们回到之前的讲过的
数据融合的例子
我们知道世界中,充满了不确定性,比如我们的模型不准确,这时候我们就可以加一点不确定性,加一个,在测量当中我们也可以加上
,这是在测量当中产生的不确定性。现在我们就是有了两个不确定性,也就是说模型也不准确,测出来的值也不准确。
在这两个都不准确的情况下,如何去测量一个精确的呢?
这就是我们卡尔曼滤波器去解决的问题
我们现在遇到的情况跟之前的也是差不多的,只不过我们现在是一个不太准的计算结果和一个不太准的测量结果,我们要根据这两个结果来估计出来一个相对准确的值。来找到一个比他们两个误差都要小的结果,这也就是我们后面要重点分析的。

卡尔曼滤波详细数学推导
引入概念
期望是什么?
在统计学和概率论中,"期望"是一个随机变量的平均值,表示该随机变量的平均预期结果。在离散随机变量的情况下,期望可以通过对所有可能取值的概率加权平均得到。在连续随机变量的情况下,期望则是对变量的值乘以其概率密度函数(PDF)进行积分得到。
设随机变量为X,它的取值为{x1, x2, ..., xn},对应的概率为{p1, p2, ..., pn},则X的期望E(X)可以表示为:
E(X) = x1p1 + x2p2 + ... + xn*pn
换句话说,期望就是所有可能取值的加权平均值。
例如,假设有一个掷骰子的游戏,骰子的点数为1到6,每个点数出现的概率都是1/6。那么掷骰子的期望就是:
E(X) = (11/6) + (21/6) + (31/6) + (41/6) + (51/6) + (61/6) = 3.5
这表示掷骰子的平均预期点数为3.5。
方差是什么?
方差是衡量随机变量离散程度的一个统计量,它表示随机变量与其期望值之间的偏离程度。如果一组数据的方差较大,则说明数据的离散程度较高;反之,方差较小则说明数据较为集中。
可以跟着一起拿纸算一下,在之前我们了解了状态空间方程的表达形式,借此来描述一个系统的动态响应
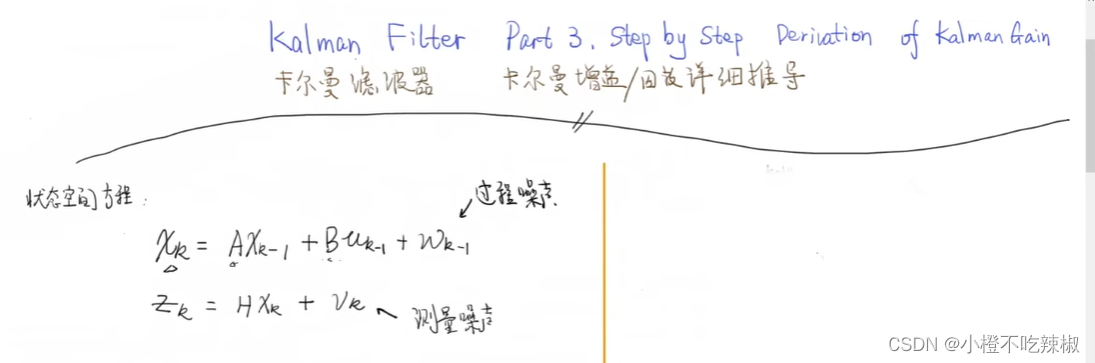
这里面我们是他的状态变量,
是他的状态矩阵,
是控制矩阵,
是控制,
是过程噪声,然后过程噪声是我们不可测的,也是我们没有办法掌握的一个内容,因为他是一个不确定性的表现,在自然界我们一般将其假设为符合正态分布,也就是他的概率分布。
他的概率分布就是也就是概率分布,0代表了它的期望,Q代表了他的协方差矩阵

然后Q又等于w乘w的转置
这个公式是怎么来的呢? 我们用简单的例子说明一下